Monte Carlo simulations are an essential and ubiquitous feature of my work as a statistical methodologist. With my students and collaborators, I have conducted simulations for nearly all of my methodological publications (and many of my blog posts, for that matter). For research simulations, I usually use factorial designs involving several factors, each with multiple levels, to explore a big space of model parameters and study design features.1 If you’ve got the infrastructure to do the computing, then it doesn’t take much further effort to run big multifactor simulations. What does become more challenging is interpreting and making sense of all the results.
For analyzing simulation results, I rely heavily on graphical representations of performance measures (such as bias, root mean-squared error, coverage, etc.). Because the simulation designs are multifactor, the graphs are usually small multiples plots (i.e., facet-grids in ggplot2 terminology). Small multiples plots can be used to represent variation in a performance measure (plotted on the vertical axis) across up to four different factors, if those factors are mapped to the horizontal axis and color (and/or stroke and/or shape), along with the horizontal and vertical facets. For designs with more than that many factors, one needs to find other ways to deal with remaining factors. That might mean creating a bunch of plots that vary across the remaining dimensions, or finding ways to marginalize across those dimensions. It can quickly become unwieldy.
For a long while now, I’ve been looking for easy ways to create more interactive visualizations of simulation results. Interactivity could be a big help with managing dimensionality, by letting a viewer iterate over different values of a parameter to see how a graph changes. Interactivity also seems useful and appealing as a way to focus in (even literally zoom in) on particular results. With the development of Quarto and support for tools like Observable.js, creating such interactive visualizations has evidently gotten much easier, even for someone (yours truly!) who knows next to nothing about web development.
In this post, I’ll give an example of an interactive visualization of simulation results to illustrate what’s possible. I’ll also comment on some alternative approaches that I’ve seen and note how they differ from the approach demonstrated here.
An example
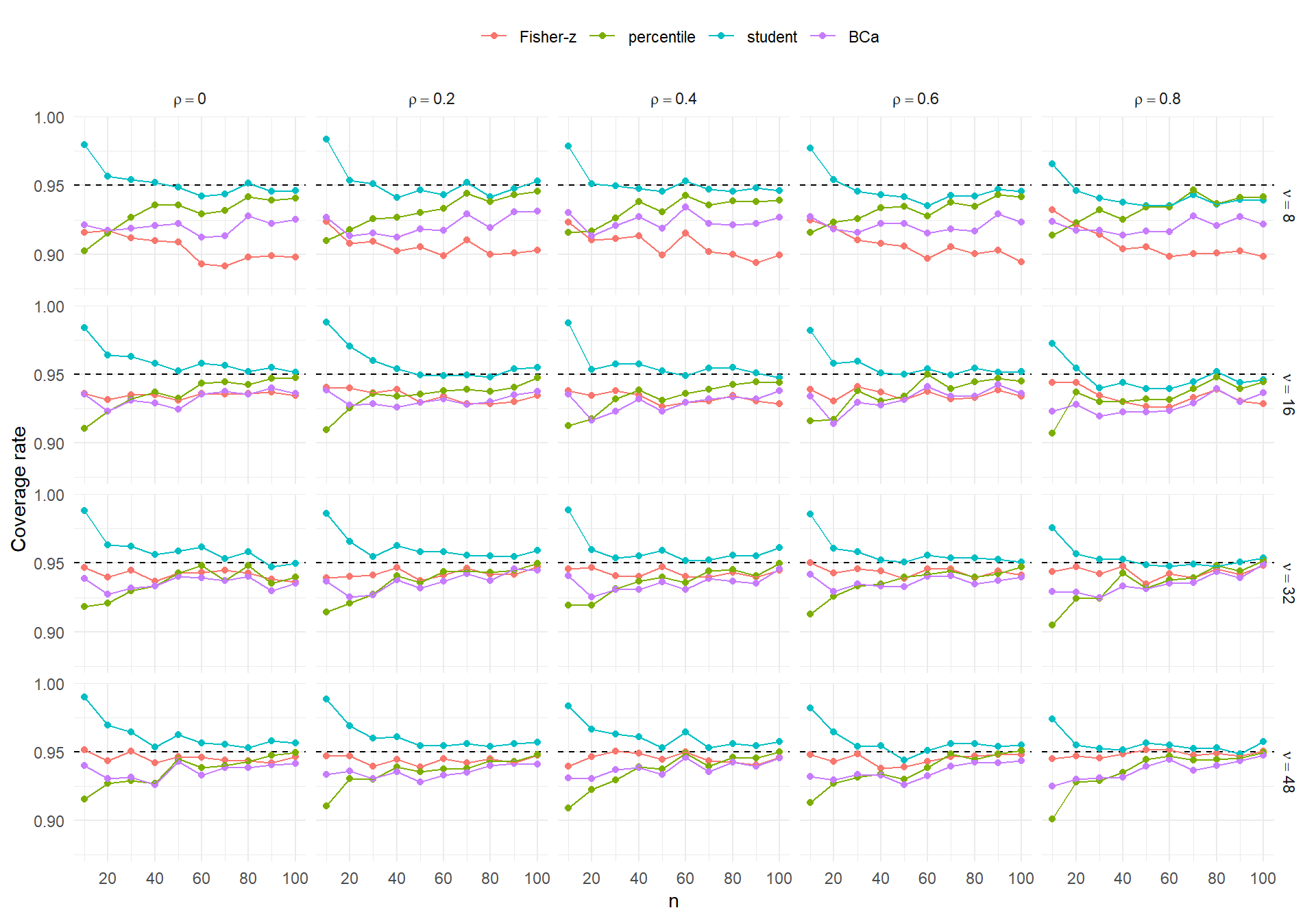
In my previous post on bootstrap confidence intervals for correlation coefficients, I represented the results of a small simulation with graphs like this one:
This graph encodes four distinct factors:
- sample size on the horizontal axis
- correlation parameter \((\rho)\) in the column facet
- degrees of freedom \((\nu)\) in the row facet
- confidence interval type, represented with color.
This was a fairly small simulation (by my standards) of a relatively simple problem. But even here, some interactivity would be appealing to allow a viewer to zoom in on a panel. It would also be nice to be able to focus in on just one or two of the interval types or to easily remove an interval type that you don’t care about.
Below is my attempt at an interactive version of this graphic. I specified the interactive tools with Observable’s inputs library. I developed the figure with Observable’s plot library. I will not get into the details of the programming because I’m still very new to both of these tools.2 Suffice it to say, I more or less followed the first example in the Quarto guide to Observable, then fiddled with the plotting code to make it look more like a ggplot2 graph.
Three of the four factors in the simulation design can be interactively filtered using the inputs to the left of the plot. (For simplicity, I kept sample size mapped to the horizontal axis and always display the full range.) Setting the correlation and degrees of freedom drop-downs to specific values lets you zoom in on a specific panel of the figure, so that it’s easier to see the fine details. In addition, the interactive figure lets you change the number of bootstraps used in the bootstrap intervals, a feature of the simulation’s design not represented in the static figure from my previous post.
This simulation only looked at a few confidence interval methods. There are others, including other bootstrap techniques, that might be interesting to add but would make a static figure very crowded and difficult to interpret. With the addition of interactivity, adding further methods might be more appealing because you could interactively filter out methods that don’t work well or that you’re not interested in.
Alternatives
I’m certainly not the first to hit on the idea of interactive display of simulation results, and there are a certainly other tools for doing this sort of thing. For one, I’ve seen several methodological papers that provide Shiny apps with such interactive visualizations. For example, Carter et al. (2019) reported a big simulation study on publication bias-correction methods in meta-analysis. They developed a Shiny app with interactive figures of the simulation results and are still serving it, five years after the paper appeared. These visualizations can be very compelling, but the implementation feels a bit heavy to me—it seems like overkill to have to run a server and regenerate figures just to see graphs. In contrast, the interactive graphic above is not hosted—it’s just a static web page.
Of course, just creating a bunch of graphs and sticking them in a pdf doesn’t seem ideal either. In this working paper with Man Chen (Chen and Pustejovsky 2024), Man hit on the idea of organizing all our graphs using tabsets to make it a bit easier to navigate all the different conditions in a big simulation. You can see the results in the supplementary materials3. I think it took a fair amount of copy-pasta to create these graphs, but it seems like the sort of thing that could be automated.
Yihui Xie has a blog post demonstrating a fairly simple javascript technique that could be used to accomplish much the same thing as Man’s tabsets or my interactive graphs. The core idea is to generate a bunch of images, covering every possible scenario the viewer might care to see, and then use simple interactive elements to determine which image gets viewed. This seems like a pretty useful approach, and one that could be automated for use in Rmarkdown- or Quarto-generated html. It seems more useful when the total number of possible graphs is fairly small.4 For visualizations with more options (and thus a greater number of unique possible states), truly interactive graphics like the one above seem like the way to go.
Where and wherefore?
Creating this interactive graph took some fiddling, but the process was quick enough that I could certainly see using this approach for future projects (not just blog posts). It will probably take a bit of experimentation to figure out exactly where this fits into my research process. Is it just an internal tool to help our team to explore simulation results? Or is it something public-facing and connected to a manuscript? If the latter, where do we put it? If the academic journal model weren’t so tied to pdf, I would love to just plop one (or more) of these into a manuscript and let readers explore our results for as long as they care to. Short of that, I suppose these graphs could be part of supplementary materials. I could also see using interactive graphs like this as part of conference presentations or teaching.
References
Carter, Evan C, Felix D. Schönbrodt, Will M Gervais, and Joseph Hilgard. 2019. “Correcting for Bias in Psychology: A Comparison of Meta-Analytic Methods.” Advances in Methods and Practices in Psychological Science 2 (2). https://doi.org/10.1177/2515245919847196.
Chen, Man, and James E Pustejovsky. 2024. Adapting Methods for Correcting Selective Reporting Bias in Meta-Analysis of Dependent Effect Sizes. MetaArXiv. https://doi.org/10.31222/osf.io/jq52s.
Footnotes
It’s not a Pusto lab simulation if it doesn’t have at least 1200 conditions in it, we say around here.↩︎
If you’d like to inspect my code just click on the
</>CODEdrop-down in the header of the post and selectVIEW SOURCE.↩︎You’ll need to download the html to view the graphs↩︎
The interactive figure above includes 6 settings for the correlation, 5 settings for the degrees of freedom, 6 settings for the number of bootstraps, and \(2^4 = 16\) settings for the combination of methods to display. In all, that comes to 2880 unique combinations of settings, times two different graphs, for a total of 5760 graphs that would need to be generated following Yihui’s approach. Each image is 69.4Kb, so the total size of the files for every possible iteration would come to 390.3Mb.↩︎